
Dealing with binary files in Git often requires separating the binary content from the rest of the source code. The typical approach is to consider Git Large File Storage (LFS). This allows that data to be stored outside of the Git data stores while still remaining accessible to the repository. This also allows Git to fetch the files on demand, shrinking the size of the repository and speeding up operations. But how does this work? What happens when you push a file to a repository that is configured to use LFS?
Let’s take a look at the secret life of Git LFS.
How Git is extended
To understand how LFS works, it’s important to first understand how Git works. While Git is developed in C, it relies heavily on shell scripts to perform many of its operations. In fact, the Windows version of Git includes a minimal Bash shell to ensure that the scripts can operate as expected. Over time, many (but not all) of the original scripts have been converted to compiled code. However, this is not the case when it comes to the main extension point – hooks.
Hooks are scripts that are executed at certain points in the Git lifecycle. This allows them to influence the results of specific operations. To do this, Git will look for files with the executable bit set in the $GIT_DIR/hooks directory (typically, .git/hooks) with a name that matches the event. If the script is found, it will be executed. If no script is present, then Git will continue with the operation.
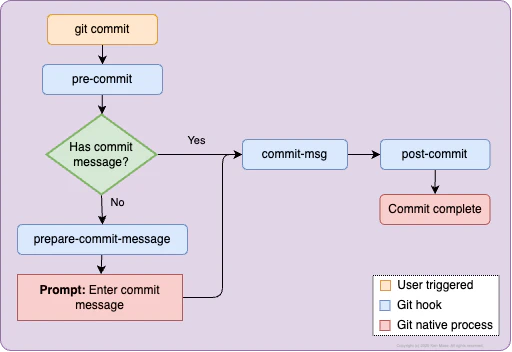
There are multiple hooks that are invoked as part of executing the git commit command:
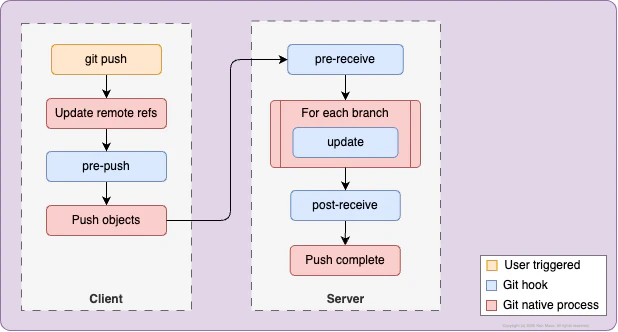
Similarly, there are client and server hooks that are invoked when you execute the git push command:
There are some additional hooks to support other operations. For example, post=checkout is run after a successful checkout and post-merge is run after a successful merge. The full list of hooks is covered in the
Git githooks documentation.
Client-side hooks are executed on the machine that is running the Git command. This is usually the developer’s machine. These hooks are not able to be committed to the repository. As a result, configured hooks are not shared with other developers. That means that the hooks must be setup or configured by each developer before they can be used. Git LFS has a trick to avoid that challenge that I’ll cover in a bit.
Git filters
Hooks aren’t the only extensibility point. There is another important one to understand: drivers. Drivers are command line executables that can be used as part of Git processes. During certain Git operations, Git will use those executables to perform the task. There are three that are important to understand for LFS:
diff- Produces a diff between two versions of a file when calling
git diff
merge- Performs a three-way merge between two versions of a file when calling operations such as
git merge,git revert, andgit cherry-pick
filter- Modifies files when they are added to the index (
git add) or checked out to the working directory (git checkout,git clone,git pull)
The diff and merge drivers are relatively simple conceptually. The each focus on a single task and return the results. The filter driver is more complex. It has the ability to change the contents of files before they are copied into the working directory and before the contents are committed to the storage. As a result, a filter driver supports up to three commands (or filters) that can be executed.
smudge- This operation is used to control the contents of a file being written to the working directory. This processes a single file in the Git object storage to generate the content that will be placed in the working directory.
clean- This operation is performed when a file is staged (via
git add). It processes a file in the working directory to generate the content that will be staged and later added to the object storage.
process- This command uses a
binary protocol to handle both smudge and clean operations for multiple files. For example, it can perform a
cleanon all of the files referenced by agit add --allcommand. Support for this approach was added in newer versions of Git to improve the performance, especially with larger repositories. Git will prefer to use this command when it is available.
Drivers are typically configured in the global gitconfig to ensure they are available for all repositories to use. For example, when you run git lfs install, it adds the following lines to the global gitconfig:
1[filter "lfs"]
2 clean = git-lfs clean -- %f
3 smudge = git-lfs smudge -- %f
4 process = git-lfs filter-process
5 required = trueThis defines the lfs filter and declares its support for the clean, smudge, and process operations. This means that Git LFS will be able to process files before they are stored and when they are copied to the working directory. When a file needs to be smudged, Git will load the contents of the file from the object store. It will then pipe the contents into the command (replacing %f with the output path).
This configuration sets the required flag to true. This means that the filter is required in order to properly process the files. If the filter is not available, Git will not be able to process the files and will return an error. It’s important to understand that this configuration is not stored in the repository; the filter must be configured on each machine that will be working with the repository. Without this configuration, the filter will not be available and the files will be treated as standard Git content.
The .gitattributes file
Once the filter is configured, we need a way to enable it for a specific repository. This is done using the .gitattributes file. It needs a mapping that tells it the filters to apply to specific file extensions or locations. Git LFS provides a helpful command that does this for you. For example, if you use git lfs track '*.iso to track all ISO files, it creates a .gitattributes file if it does not exist. It then adds this line:
*.iso filter=lfs diff=lfs merge=lfs -textThis configures Git to use the LFS filter. In addition, it marks the file as a binary (-text) and tells Git to use the LFS driver for the diff and merge operations. Essentially, this tells Git to compare the raw pointer files.
It’s worth knowing that you can limit the filtering to a specific directory (for example, using images/*.iso instead of *.iso to handle the ISOs in the images folder or images/**/*.iso to recursively handle the files). This can allow you to fine-tune the behavior of the filter and its attributes.
The Git LFS filter
Now that you have a basic understanding of hooks and filters, let’s understand how this relates to Git LFS. The primary behavior of Git LFS is implemented as a filter driver. That means that it performs clean and smudge operations. This is the first step in processing the binary files.
When you add an LFS tracked file (via git add), the LFS clean filter writes the binary contents to .git/lfs/objects. It then returns a newline (\n) separated file containing key-value pairs called the pointer file. The pointer file is then staged. As an example (from the
specifications), a pointer file looks like this:
1version https://git-lfs.github.com/spec/v1
2oid sha256:4d7a214614ab2935c943f9e0ff69d22eadbb8f32b1258daaa5e2ca24d17e2393
3size 12345The Git repository is now tracking this small pointer file, while LFS is storing the binary content in the object storage.
Similarly, when Git does a checkout on a file that is being tracked by LFS, the smudge filter is applied. The filter reads the first 100 bytes of the file to determine if it is a valid pointer file. If it isn’t, the filter returns the contents of the file without modification. If it is, the filter reads the pointer file to determine the OID of the file containing the binary data. It then looks for the file in .git/lfs/objects. If the file is found, the filter returns its contents. If the file is not found, the filter will download the file from the LFS server, store it in .git/lfs/objects, and return its contents.
We’re still missing one piece of the puzzle. Not everything in Git’s object storage is pushed back to the server. How does Git LFS make sure that its storage in .git/lfs/objects is pushed to the server? This is where the hooks come in.
Git LFS hooks
To be able to manage the LFS binary data, Git LFS uses a set of hooks. Since hooks are not automatically stored as part of the repository, it uses a few tricks to make sure that they get configured properly. The first is the git lfs install command. Beyond setting up the gitconfig, this command also writes four hook scripts in the .git/hooks directory:
- post-checkout
- post-commit
- post-merge
- pre-push
Each script has the same basic structure. First, it runs command -v git-lfs >/dev/null 2>&1 to determine if Git LFS is installed and available. If it is not, it will return an error message. After that, it will call git lfs $HOOK_NAME "$@". This invokes git-lfs, passing in the name of the hook and all of the parameters provided to the hook. This ensures the LFS executable is invoked for each of these hooks.
That works for the initial installation. To ensure it continues to work, Git LFS also creates (or updates) the scripts whenever the filter is invoked for clean or smudge operations. For example, when a repository is cloned (or the latest content is pulled), Git will read the .gitattributes file and apply the smudge filter to any tracked file extensions. That will cause the hooks to be created or updated. Similarly, if you use git lfs clone to clone an LFS-enabled repository, it will create the hooks as part of the operation.
Three of the hooks (post-checkout, post-commit, and post-merge) provide some logic for handling files that are locked by another user. In this case, the hooks will try to mark locked files as read-only. I won’t dive into the details of how Git LFS file locking works in this post.
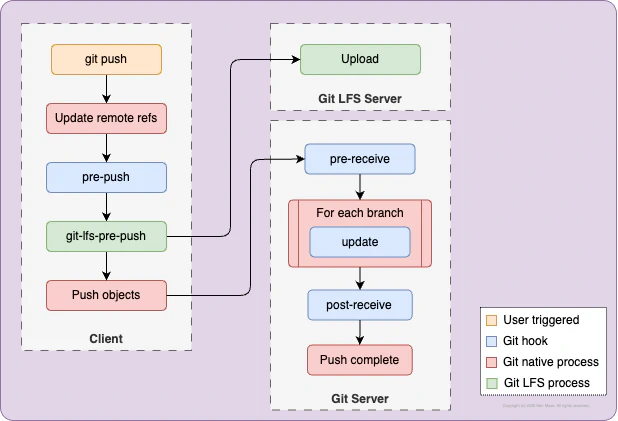
The final hook, pre-push is the most important. This is the last hook invoked before a set of changes is pushed to a remote repository. When it is invoked, it receives a range of commits. Git LFS examines these to determine if there are any associated Git LFS objects. The discovered Git LFS objects are then pushed to the Git LFS server using HTTPS. If it fails, then git push operation will be aborted with an error message.
As a result, the final flow for Git LFS looks like this:
Composing with Git
The design of Git allows us to compose solutions that change the behavior of the system. In this case, adding support for extracting and storing large files outside of the main Git repository. Git LFS shows how filters and hooks can be used to extend Git’s capabilities in very significant ways. Git LFS also offers its own extensibility points, so the story doesn’t end here! This also illustrates how an installed filter can be used to automatically configure and manage hooks. This can provide a powerful way to influence the functionality or to capture important metrics or details during the process.